
Stata的predict命令是回归分析后不可或缺的工具,主要用于根据已估计的模型结果计算预测值、残差、各种拟合优度指标及其他衍生统计量,该命令的灵活性和强大功能使其成为实证分析中从基础预测到高级诊断的核心操作,本文将详细解析predict命令的语法结构、主要功能选项、实际应用场景及注意事项。

predict命令的基本语法结构为“predict [类型] [新变量名] [if] [in] [, options]”,类型”指定要计算的统计量,“新变量名”为生成的变量命名,“if”和“in”用于限定样本范围,“options”则根据模型类型提供不同参数,值得注意的是,predict命令必须在估计模型(如regress、logit、xtreg等)之后立即使用,因为Stata会临时存储模型的估计结果(如系数、方差等),这些结果在下次估计新模型时会被覆盖。
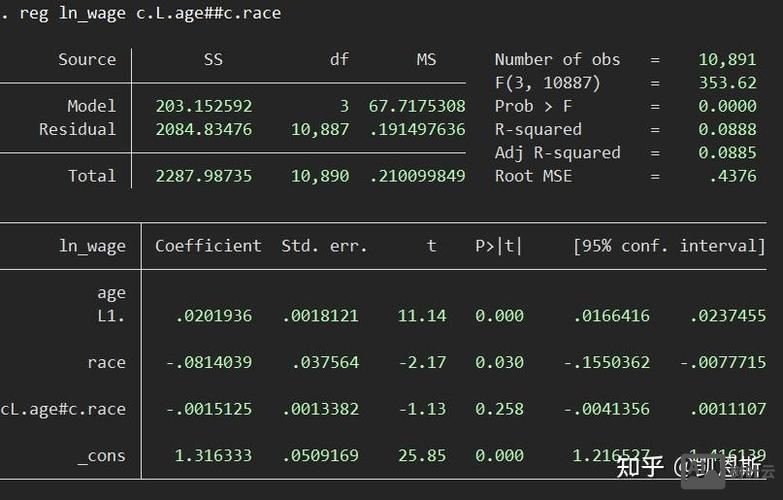
根据模型类型不同,predict命令的主要功能选项可分为三大类:预测值类、残差类和模型统计量类,预测值类选项中最常用的是“xb”,即计算线性预测值,对于线性回归模型,其公式为(\hat{y} = X\beta);对于广义线性模型(如logit),则需指定“pr”计算预测概率,“ir”计算风险比(incidence rate ratio),“xb”仍计算线性预测项的指数形式,在logit回归后使用“predict y_pr, pr”可生成事件发生的预测概率,面板数据模型中,“predict”还支持“u”和“e”选项分别提取个体效应和时变残差,有助于分析随机效应或固定效应的构成。
残差类选项是模型诊断的重要工具。“residuals”(或简写“r”)计算普通残差(y – \hat{y});“rstandard”计算标准化残差,消除量纲影响;“rstudent”计算学生化残差,用于识别异常值;“predict”还支持“anscombe”计算Anscombe残差,适用于泊松或负二项回归等非正态分布模型,在异方差检验前,可通过“predict stdres, rstandard”生成标准化残差,再结合“rvfplot”绘制残差图,对于时间序列模型,“predict”的“dynamic()”选项可实现动态预测,适用于ARIMA等模型的事后预测分析。
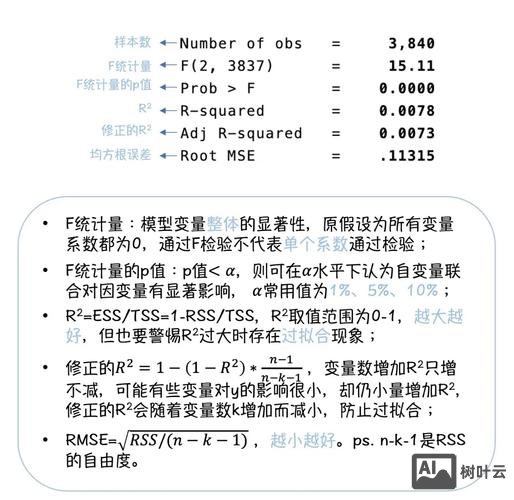
模型统计量类选项则提供模型拟合优度的衍生指标。“hat”计算杠杆值(leverage),用于识别高杠杆点;“predict”的“deviance”和“pearson”分别计算偏差和Pearson卡方统计量,常用于GLM模型拟合优度评估;“sigma_u”和“sigma_e”在混合效应模型中提取组间和组内标准差,计算组内相关系数(ICC),在多层级模型(xtmixed)后,通过“predict icc, reffects”可提取随机效应,进而计算ICC以衡量组间方差占比。
实际应用中,predict命令需注意样本范围的一致性,如果估计模型时使用了“if”条件,预测时也应保持相同样本,否则可能产生错误,不同模型对选项的支持存在差异,如“poisson”模型不支持“ir”选项,需通过“glm”命令的“link(log)”和“eform”选项实现类似功能,对于非线性预测(如预测logit模型的边际效应),需结合“margins”命令,而非直接使用“predict”。
以下是部分常用选项的总结:
| 选项类别 | 选项名称 | 功能描述 | 适用模型 |
|---|---|---|---|
| 预测值类 | xb | 线性预测值 | 所有模型 |
| pr | 预测概率 | logit, probit | |
| ir | 风险比 | logit, poisson | |
| 残差类 | residuals | 普通残差 | 所有模型 |
| rstandard | 标准化残差 | 线性模型 | |
| rstudent | 学生化残差 | 线性模型 | |
| 模型统计量类 | hat | 杠杆值 | 线性模型 |
| deviance | 偏差统计量 | GLM | |
| sigma_u | 组间标准差 | 面板/混合效应模型 |
在使用predict命令时,还需警惕模型假设的违背问题,若线性回归存在异方差,普通残差的分析可能失真,此时应结合“predict”生成加权残差(如“predict wres, residuals”后使用“predict wresw=wres/sqrt(h)”),对于分类因变量模型的预测概率,需注意“pr”选项返回的是预测概率值,而非分类结果,若需生成0/1预测变量,需进一步设定阈值(如“generate y_pred=(y_pr>0.5)”)。
相关问答FAQs:
Q1: 为什么在logit回归后使用“predict y_pr, pr”生成的预测概率值全部为0或1?
A1: 可能的原因包括:①模型存在完全分离(perfect separation),导致系数估计值极大,预测概率趋近0或1;②样本量过小或自变量过多,导致模型过拟合,可通过检查“logit”估计后的“condition number”或使用“estat gof”进行拟合优度检验,若存在完全分离,需通过增加样本、合并类别或采用Firth偏似然回归(“firthlogit”)解决。
Q2: 如何在面板数据固定效应模型后,同时预测个体效应和时变残差?
A2: 使用“xtreg fe”估计固定效应模型后,可通过两次“predict”命令分别提取个体效应(u)和时变残差(e),具体步骤为:①“predict u, u”生成个体效应变量;②“predict e, e”生成时变残差,注意,固定效应模型中的个体效应是估计的固定参数,而随机效应模型中的“u”代表随机效应,需通过“predict”的“reffects”选项提取,个体效应与残差的和即为模型的拟合值(“predict y_hat, xb”)。
文章来源网络,作者:管理,如若转载,请注明出处:https://shuyeidc.com/wp/478071.html<