
Linux性能监控是系统管理和运维中的核心任务,通过命令行工具可以高效获取系统资源使用情况、进程状态及性能瓶颈,以下从CPU、内存、磁盘、网络及综合监控五个维度,详细介绍常用命令及其使用方法。
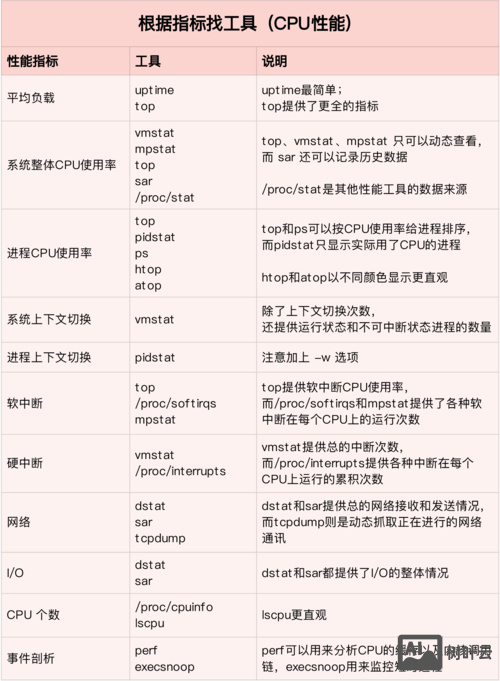

CPU性能监控
CPU是系统的核心,监控需关注使用率、负载、上下文切换及进程级占用情况。
top – 实时进程级监控
top以动态列表形式展示进程资源占用,默认按CPU使用率排序,常用参数:
-d:刷新间隔(如top -d 2每2秒刷新)。-p:监控指定进程(如top -p 1234)。-c:显示完整命令行而非仅进程名。-b:批量输出模式,适合脚本处理(如top -b -n 5 > top.log)。
关键字段:
%us(用户态CPU)、%sy(内核态CPU)、%id(空闲)、%wa(等待I/O)。load average:1分钟/5分钟/15分钟系统负载,理想值应不超过CPU核心数。
vmstat – 虚拟内存统计(含CPU)
vmstat报告进程、内存、I/O、CPU等摘要信息,常用参数:
1:每秒刷新一次(如vmstat 1)。-s:以统计表形式展示详细计数器。
关键字段:
r:运行队列进程数(长期大于CPU核心数则负载过高)。us、sy、id、wa:同top的CPU指标。cs:上下文切换次数,频繁切换可能意味着进程过多或CPU竞争。
mpstat – 多核CPU监控
mpstat是sysstat工具包的一部分,可按核心拆分CPU使用率。
-P ALL:显示所有核心的CPU使用情况(如mpstat -P ALL 1)。usr、sys、idle:各核心的用户态、内核态、空闲占比。
内存性能监控
内存监控需关注使用率、空闲/缓冲/缓存分布,以及进程内存占用。
free – 内存使用概览
free以易读格式显示内存总量、已用、空闲、缓冲/缓存等信息。

-h:以人类可读格式显示(如free -h)。-m:以MB为单位。
关键字段:
total:总内存。used:已用内存(包含内核缓冲/缓存)。free:完全空闲内存。buff/cache:缓冲(块设备缓存)和缓存(文件页缓存),可通过释放缓存临时释放内存(如echo 1 > /proc/sys/vm/drop_caches)。
smem – 精确内存占用统计
smem可区分物理内存(RSS)和虚拟内存(Swap),支持按进程/用户/命令分组。
-p:按进程排序(如smem -p)。-k:以KB为单位显示。USS(Unique Set Size):进程独占物理内存,比RSS更准确反映内存占用。
磁盘I/O监控
磁盘I/O瓶颈会导致系统响应缓慢,需关注吞吐量、I/O延迟及队列长度。
iostat – I/O设备统计
iostat是sysstat工具包组件,可监控磁盘及CPU使用情况。
-d:仅显示磁盘I/O统计(如iostat -d 1)。-x:扩展统计,包含关键指标:%util:磁盘利用率(超过70%可能存在瓶颈)。await:平均I/O等待时间(毫秒),过高意味着磁盘响应慢)。r_await/w_await:读/写平均等待时间。
iotop – 实时I/O进程监控
iotop以类似top的界面实时显示各进程的I/O读写速度,需root权限。
-o:仅显示正在产生I/O的进程。-p:监控指定进程。
dstat – 综合系统资源监控
dstat可同时监控CPU、内存、磁盘、网络等,支持自定义输出格式。
dstat -tdn:显示磁盘I/O、网络吞吐及时间(t时间、d磁盘、n网络)。
网络性能监控
网络监控需关注带宽使用、连接数、错误包及协议分布。
iftop – 实时带宽监控
iftop按主机/端口显示实时网络带宽使用情况,需root权限。
-i:指定网卡(如iftop -i eth0)。-n:以数字形式显示主机名,避免DNS解析延迟。
nethogs – 进程级网络监控
nethogs按进程统计实时网络流量,可定位占用带宽的进程。
-d:刷新间隔(如nethogs -d 2)。-c:刷新次数(如nethogs -c 5)。
ss/netstat – 网络连接状态
ss -tuln:显示TCP/UDP监听端口(-tTCP、-uUDP、-l仅监听、-n数字格式)。ss -s:摘要统计(如TCP连接数、TIME_WAIT状态数)。
综合监控工具
glances – 全能系统监控
glances基于Python开发,整合CPU、内存、磁盘、网络、进程等信息,支持Web界面和告警。
-b:显示磁盘I/O条形图。-m:显示内存使用情况。-1:单行模式,适合远程查看。
sar – 系统活动历史报告
sar是sysstat工具包的核心组件,可记录历史性能数据,用于长期分析。
-u:CPU使用率(如sar -u 5 10每5秒采样10次)。-r:内存使用率(如sar -r)。-b:I/O传输率(如sar -b)。
性能监控指标总结表
| 监控维度 | 核心命令 | 关键指标 |
|---|---|---|
| CPU | top/vmstat | %us、%sy、%id、%wa、load average、cs(上下文切换) |
| 内存 | free/smem | used、free、buff/cache、USS(进程独占内存) |
| 磁盘I/O | iostat/iotop | %util、await、r_await/w_await、读写速度 |
| 网络 | iftop/nethogs | 带宽使用、进程级流量、连接数(ss -s) |
| 综合 | glances/sar | 整合CPU、内存、磁盘、网络指标,支持历史数据分析 |
相关问答FAQs
Q1:如何判断CPU是否过载?
A1:CPU过载可通过以下指标综合判断:
- 系统负载:
load average(1分钟/5分钟/15分钟)持续超过CPU核心数(如4核CPU负载>4)。 - CPU使用率:
top或vmstat中%us+%sy长期超过80%,且%id(空闲)低于20%。 - 上下文切换:
vmstat中cs(上下文切换次数)频繁,如每秒超过10万次(需结合CPU核心数判断)。 - 运行队列:
vmstat中r(运行队列进程数)长期大于CPU核心数,表示进程等待CPU时间过长。
Q2:如何定位内存泄漏的进程?
A2:定位内存泄漏进程的步骤如下:
- 对比内存占用:使用
ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem查看进程内存占用,结合free -h观察总内存变化。 - 跟踪进程内存增长:通过
watch -n 5 'ps -p <PID> -o rss,vsz'监控目标进程的RSS(物理内存)和VSZ(虚拟内存)是否持续增长。 - 使用
smem分析:运行smem -p查看进程的USS(独占内存),若USS持续增长则可能存在泄漏。 - 检查内存分配:对于特定进程(如Java应用),可通过
jmap -histo <PID>(Java)或valgrind工具分析内存分配情况。
文章来源网络,作者:管理,如若转载,请注明出处:https://shuyeidc.com/wp/480689.html<