
核心思路解析
要从字符串中提取中间的数字部分,通常需要结合以下步骤:

(图片来源网络,侵删)
- 定位数字的起始和结束位置:通过正则表达式或字符遍历确定连续数字的范围;
- 截取子串:利用
SUBSTRING/SUBSTR等函数提取目标区间的内容; - 类型转换:将结果转为数值类型以便后续计算。
不同数据库对函数的支持略有差异,但逻辑相通,以下是主流数据库的具体实现方式:
通用方法(基于标准 SQL)
✅ 适用场景:大多数支持基础字符串函数的数据库(如 MySQL、PostgreSQL、SQL Server)
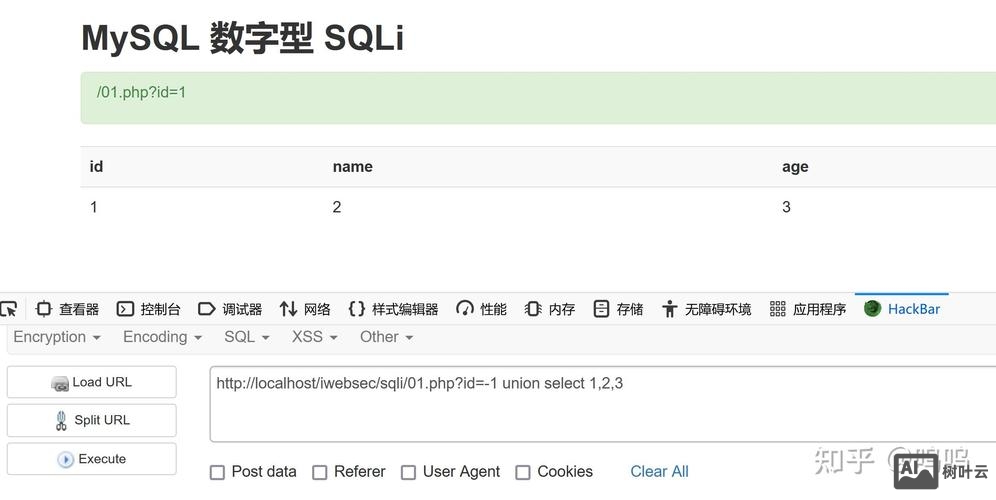
假设有一个表 test_table,其中一列 mixed_column 存储了类似 "AB123CD456EF" 的数据,目标是提取中间的数字块(456),以下是分步解决方案:
| 步骤 | 操作 | 说明 |
|---|---|---|
| 1 | 使用 PATINDEX/INSTR 查找第一个数字的位置 | SQL Server: PATINDEX('%[0-9]%', mixed_column)其他数据库: INSTR(mixed_column, '0') |
| 2 | 反向查找最后一个数字的位置 | SQL Server: LEN(mixed_column) PATINDEX('%[^0-9]%', REVERSE(mixed_column)) + 1其他数据库需手动反转字符串后重复步骤 1 |
| 3 | 计算子串长度并截取 | SUBSTRING(mixed_column, start_pos, end_pos start_pos + 1) |
| 4 | 转换为整数类型 | CAST(... AS INT) 或 CONVERT(INTEGER, ...) |
🔍 完整示例代码(以 SQL Server 为例):
SELECT
CAST(
SUBSTRING(
mixed_column,
PATINDEX('%[0-9]%', mixed_column), -起始位置
PATINDEX('%[^0-9]%', REVERSE(mixed_column)) PATINDEX('%[0-9]%', mixed_column) + 1 -长度计算
) AS INT
) AS extracted_number
FROM test_table;注意:若字段中存在多个分散的数字段(如
A1B2C3D),此方法仅能提取第一组连续数字,如需处理复杂情况,需引入正则表达式扩展功能。
按数据库分类的高级实现
📌 1. SQL Server / MS Access
优势在于内置丰富的字符串处理函数:
(图片来源网络,侵删)
- 关键函数组合:
PATINDEX,REVERSE,LEN,SUBSTRING - 进阶技巧:当知道固定格式时(如总长度恒定),可直接硬编码索引值,若始终是第 5~8 位为数字:
SELECT SUBSTRING(mixed_column, 5, 4) AS middle_digits FROM test_table;
📌 2. MySQL / MariaDB
推荐使用 REGEXP_SUBSTR(MySQL 8.0+ 支持):
SELECT CAST(REGEXP_SUBSTR(mixed_column, '[0-9]+') AS UNSIGNED) AS extracted_num FROM test_table;
对于旧版本,可用 LOCATE + SUBSTRING 模拟:
SET @start := LOCATE('0', mixed_column);
SET @end := LOCATE('9', REVERSE(mixed_column), 1);
-然后动态构建 SUBSTRING 参数...📌 3. PostgreSQL
原生支持正则表达式,语法更简洁:
SELECT (regexp_matches(mixed_column, '\d+'))[1]::INT AS extracted_num FROM test_table;
此语句直接返回第一个匹配到的数字组并转为整数。
(图片来源网络,侵删)
📌 4. Oracle
使用 REGEXP_SUBSTR 实现精准抽取:
SELECT TO_NUMBER(REGEXP_SUBSTR(mixed_column, '\d+')) AS extracted_num FROM test_table;
提示:Oracle 的正则引擎性能优异,适合大数据量下的复杂模式匹配。
特殊场景应对策略
🔧 情况 1:多个独立数字段并存
ID-123-XYZ-456-END,若需提取第二个数字段 456:
- 方案:先用
SPLIT_PART(PostgreSQL)或分层解析:SELECT SPLIT_PART(regexp_split_to_array(mixed_column, '[^0-9]+'), 2)::INT;
- 原理:先将非数字字符作为分隔符拆分成数组,再取指定索引的元素。
🔧 情况 2:前导/后缀干扰字符
如 >>>123<<<,可通过修剪空白符优化:
SELECT LTRIM(RTRIM(SUBSTRING(...))) AS cleaned_num; -去除前后空格或其他特定字符
🔧 情况 3:无数字时的容错处理
添加 CASE WHEN 判断避免报错:
SELECT CASE WHEN PATINDEX('%[0-9]%', mixed_column) > 0 THEN ... ELSE NULL END;性能对比与选型建议
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 基础字符串函数 | 兼容性好 | 代码冗长,维护成本高 | 简单场景,跨库兼容 |
| 正则表达式 | 简洁强大,灵活度高 | 部分旧版数据库不支持 | 现代数据库首选 |
| 专用解析函数 | 高效精准 | 学习曲线较陡 | 复杂格式标准化处理 |
相关问答 FAQs
Q1: 如果字段中没有数字怎么办?如何避免错误?
A1: 使用条件判断包裹提取逻辑,
SELECT CASE WHEN PATINDEX('%[0-9]%', mixed_column) > 0 THEN CAST(SUBSTRING(...) AS INT) ELSE NULL END;或者在应用层设置默认值(如 COALESCE(extracted_num, 0))。
Q2: 为什么有时提取结果是科学计数法格式?(如 23E+06)
A2: 这是由于数据库自动将大整数转为浮点型显示所致,强制转换为 DECIMAL 或 BIGINT 可解决:
SELECT CAST(SUBSTRING(...) AS DECIMAL(20,0)); -保留完整精度
文章来源网络,作者:管理,如若转载,请注明出处:https://shuyeidc.com/wp/312144.html<