
获取meta标签的属性值是前端开发中常见的需求,meta标签通常用于提供文档的元数据,如描述、关键词、字符编码、视口设置等,在JavaScript中,可以通过多种方法获取meta标签的属性值,以下是详细的操作步骤和示例。
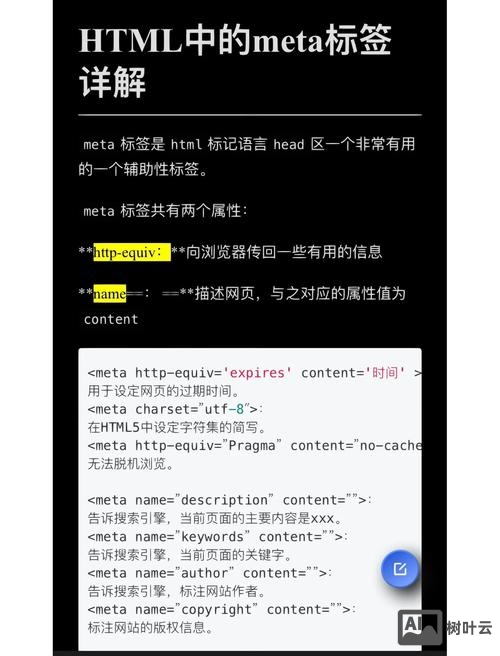

了解meta标签的基本结构,meta标签通常位于HTML文档的head部分,常见的属性包括name、content、http-equiv、charset等。<meta name="description" content="这是一个示例描述">,其中name和content是属性,我们需要获取的是content的值,获取meta标签属性值的方法主要有以下几种:
使用document.querySelector()方法
document.querySelector()方法可以通过CSS选择器获取匹配的第一个元素,对于meta标签,可以使用属性选择器来定位特定的meta标签,要获取name为”description”的meta标签的content属性值,可以这样写:
const metaDescription = document.querySelector('meta[name="description"]').content;
console.log(metaDescription); // 输出:这是一个示例描述如果meta标签有其他属性,比如http-equiv,也可以通过类似的方式获取:
const metaCharset = document.querySelector('meta[charset]').charset;
console.log(metaCharset); // 输出:UTF-8使用document.getElementsByTagName()方法
document.getElementsByTagName()方法返回一个包含所有匹配标签的HTMLCollection,通过遍历这个集合,可以找到特定的meta标签并获取其属性值。
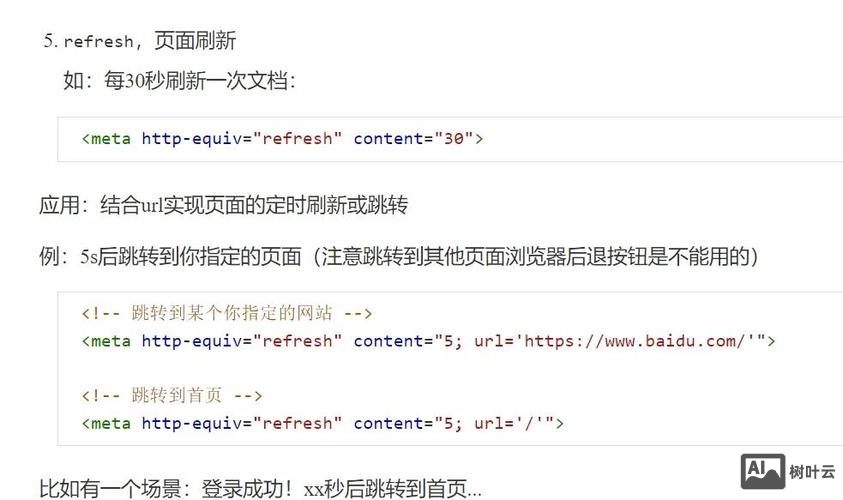
const metaTags = document.getElementsByTagName('meta');
for (let i = 0; i < metaTags.length; i++) {
if (metaTags[i].name === 'description') {
console.log(metaTags[i].content);
break;
}
}这种方法适用于需要遍历所有meta标签的情况,但效率可能不如querySelector()高。
使用document.head.querySelector()方法
如果meta标签位于head部分,可以直接通过document.head.querySelector()来获取,这样可以缩小搜索范围,提高性能:
const metaKeywords = document.head.querySelector('meta[name="keywords"]').content;
console.log(metaKeywords); // 输出:关键词1,关键词2获取多个meta标签的属性值
有时候需要获取多个meta标签的属性值,比如所有name为”viewport”的meta标签,可以使用document.querySelectorAll()方法,它返回一个NodeList,可以遍历获取所有匹配的元素:
const viewportMetas = document.querySelectorAll('meta[name="viewport"]');
viewportMetas.forEach(meta => {
console.log(meta.content);
});处理动态加载的meta标签
如果meta标签是通过JavaScript动态加载的,需要在DOM更新后获取属性值,可以使用MutationObserver来监听DOM的变化,并在meta标签添加后获取其属性值:

const observer = new MutationObserver(mutations => {
mutations.forEach(mutation => {
if (mutation.addedNodes.length) {
const newMeta = document.querySelector('meta[name="new-meta"]');
if (newMeta) {
console.log(newMeta.content);
observer.disconnect(); // 获取后停止监听
}
}
});
});
observer.observe(document.head, { childList: true });错误处理
在实际开发中,可能需要处理meta标签不存在的情况,可以通过检查获取的元素是否存在来避免错误:
const meta = document.querySelector('meta[name="nonexistent"]');
if (meta) {
console.log(meta.content);
} else {
console.log('未找到指定的meta标签');
}实际应用示例
假设我们需要获取页面的描述信息,并在页面上显示:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta name="description" content="这是一个示例页面">示例页面</title>
</head>
<body>
<h1>页面描述</h1>
<p id="description"></p>
<script>
const metaDescription = document.querySelector('meta[name="description"]').content;
document.getElementById('description').textContent = metaDescription;
</script>
</body>
</html>常见meta标签及获取方法
以下是常见meta标签的示例和获取方法:
| meta标签属性 | 示例 | 获取方法 |
|---|---|---|
| name=”description” | <meta name="description" content="页面描述"> | document.querySelector('meta[name="description"]').content |
| name=”keywords” | <meta name="keywords" content="关键词1,关键词2"> | document.querySelector('meta[name="keywords"]').content |
| name=”viewport” | <meta name="viewport" content="width=device-width, initial-scale=1.0"> | document.querySelector('meta[name="viewport"]').content |
| http-equiv=”Content-Type” | <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> | document.querySelector('meta[http-equiv="Content-Type"]').content |
| charset | <meta charset="UTF-8"> | document.querySelector('meta[charset]').charset |
相关问答FAQs
问题1:如果meta标签没有name属性,如何通过其他属性获取?
解答:如果meta标签没有name属性,可以通过其他属性如http-equiv、charset或property来获取,对于http-equiv属性,可以使用document.querySelector('meta[http-equiv="Content-Type"]').content;对于charset属性,可以使用document.querySelector('meta[charset]').charset。
问题2:如何确保在动态加载的meta标签渲染完成后获取其属性值?
解答:可以使用MutationObserver来监听DOM的变化,当检测到新的meta标签被添加时,再获取其属性值。
const observer = new MutationObserver(() => {
const newMeta = document.querySelector('meta[name="dynamic"]');
if (newMeta) {
console.log(newMeta.content);
observer.disconnect();
}
});
observer.observe(document.head, { childList: true });这样可以在meta标签动态加载后安全地获取其属性值。
文章来源网络,作者:运维,如若转载,请注明出处:https://shuyeidc.com/wp/349929.html<