
火车头采集如何设置是许多需要进行数据爬取的用户关心的问题,火车头采集器是一款功能强大的网络数据采集工具,通过合理的设置可以高效地抓取目标网站的数据,下面将详细介绍火车头采集的设置步骤和注意事项,帮助用户快速上手。

安装与启动
首先需要从火车头采集器的官方网站下载最新版本的安装包,根据提示完成安装,安装完成后,双击桌面图标启动程序,进入主界面,首次使用时,建议先注册一个账号,以便保存采集任务和配置信息。
创建新任务
在主界面点击“新建任务”按钮,弹出任务创建窗口,需要填写任务名称(如“新闻采集”)、选择任务类型(一般为“自定义采集”),并设置任务保存路径,任务名称建议使用有意义的标识,方便后续管理;保存路径需确保有足够的磁盘空间,且用户具有读写权限。
配置网址采集规则
网址采集规则是确定从哪些页面抓取数据的关键,在任务配置界面,切换到“网址设置”选项卡,主要配置以下参数:
- 起始网址:输入需要采集的目标网站首页或具体栏目页的URL,支持多网址批量输入,每行一个网址。
- 采集网址过滤规则:通过正则表达式或通配符筛选符合条件的网址,仅采集包含“news/2023”的网址,可设置规则为“news/2023”,若需排除特定网址,可在“排除规则”中设置,如排除“login”页面。
- 翻页设置:对于需要分页的网站,需配置翻页规则,支持多种翻页方式,如“静态翻页”(通过URL中的页码参数,如“?page=1”)、“动态翻页”(通过JS点击事件模拟)或“列表页提取”(从列表页中提取下一页链接),需根据目标网站的实际结构选择合适的翻页方式,并设置最大页数限制,避免无限采集。
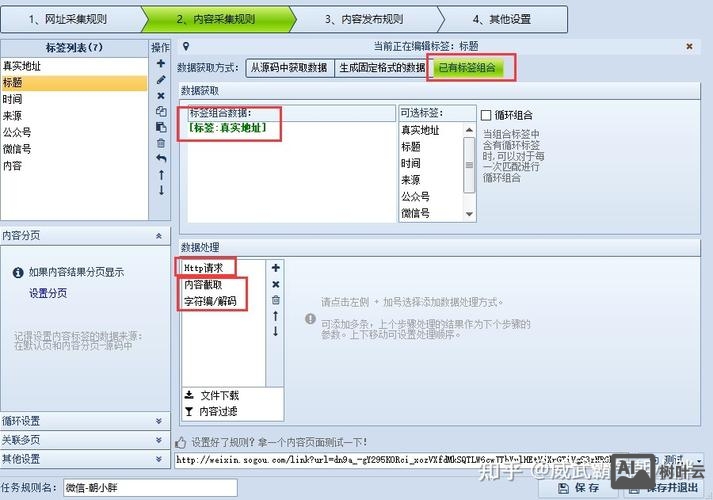
采集规则采集规则用于定义需要抓取的具体字段,如标题、正文、发布时间、作者等,在“内容设置”选项卡中,点击“添加字段”逐一定义:
- 字段名称:输入字段的标识,如“title”、“content”。
- 抓取方式:选择“选择范围”或“正则表达式”,对于结构化较强的HTML页面,优先使用“选择范围”,通过鼠标在目标页面上选中需要抓取的内容,程序会自动生成对应的XPath或CSS选择器;对于动态加载或复杂结构的内容,可使用“正则表达式”手动编写匹配规则。
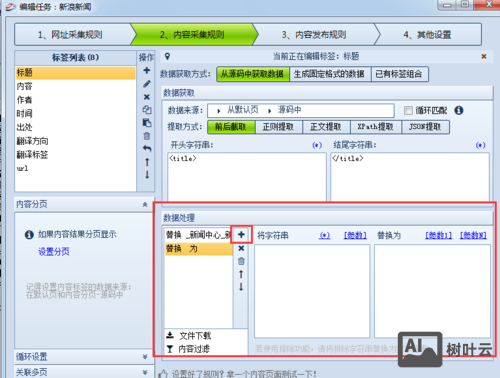
- 字段处理:可对抓取的数据进行二次处理,如去除HTML标签(使用“去除HTML”功能)、截取字符串(使用“截取”功能)、替换文本(使用“替换”功能)等,抓取的正文包含广告内容,可通过正则表达式“广告”替换为空字符串。
- 循环抓取:对于列表页中的多条数据,需设置循环抓取规则,通常选择“循环列表”,然后通过鼠标选中列表项的父级容器(如包含每条新闻的
<li>或<div>标签),程序会自动识别列表中的重复结构并批量抓取。
高级设置
在“高级设置”选项卡中,可配置更精细的采集参数:
- 请求设置:设置请求头信息(如User-Agent、Referer),模拟浏览器访问,避免被网站识别为爬虫;设置请求超时时间(默认为30秒,可根据网络状况调整);启用代理IP(需提前导入代理池),防止因频繁请求导致IP被封禁。
- 编码设置:根据目标网站的字符编码选择正确的编码格式(如UTF-8、GBK),避免出现乱码,若不确定编码,可勾选“自动检测编码”。
- 采集间隔:设置两次请求之间的时间间隔(如1-3秒),降低对目标网站的访问压力,提高采集成功率。
- Cookie设置:对于需要登录才能访问的网站,需在“Cookie管理”中导入登录后的Cookie信息,确保采集到需要权限的数据。
保存与测试
完成所有配置后,点击“保存任务”按钮,在正式采集前,建议先进行测试:切换到“测试”选项卡,输入一个起始网址,点击“开始测试”,观察抓取的字段数据是否符合预期,若字段为空或数据错误,需返回“内容设置”检查选择器或正则表达式是否正确,可通过“元素查选”功能(通常按F12键)在目标页面中精确定位HTML节点。
执行采集与导出
测试通过后,切换到“采集”选项卡,点击“开始采集”按钮,程序会按照配置的规则自动抓取数据,并在界面中显示采集进度和已采集数据条数,采集完成后,可在“数据管理”中查看、编辑或删除已采集的数据,支持将数据导出为多种格式,如Excel、CSV、TXT、数据库等,点击“导出”按钮选择目标格式即可。
注意事项
- 遵守网站规则:采集前需查看目标网站的robots.txt协议,确认是否允许爬虫抓取,避免采集受保护的内容或违反网站使用条款。
- 反爬应对:若遇到验证码、IP封禁等问题,可通过更换User-Agent、设置代理IP、降低采集频率等方式解决;部分网站可能需要处理动态加载(如AJAX请求),此时需使用“抓取AJAX数据”功能或分析接口地址直接请求。
- 数据备份:定期备份采集任务配置和已采集数据,防止因程序崩溃或误操作导致数据丢失。
- 合法合规:确保采集的数据不涉及侵犯版权、隐私等法律问题,仅用于合法用途。
相关数据采集规则配置示例表
| 字段名称 | 抓取方式 | 选择器/正则表达式示例 | 处理方式 |
|———-|—————-|—————————-|————————| | 选择范围 | //h1[@class=”title”]/text() | 无 | | 选择范围 | //div[@class=”content”] | 去除HTML |
| 发布时间 | 正则表达式 | (\d{4}-\d{2}-\d{2}) | 截取前10位 |
| 作者 | 选择范围 | //span[@class=”author”] | 替换“作者:”为空字符串 |
相关问答FAQs
Q1:火车头采集时提示“访问被拒绝”怎么办?
A:这通常是因为目标网站的反爬机制拦截了请求,可尝试以下方法解决:1)在“高级设置”中更换更常见的User-Agent(如Chrome浏览器的UA);2)启用代理IP,在“代理设置”中导入可用代理;3)延长采集间隔,将“采集间隔”设置为3-5秒;4)检查请求头中的Referer是否正确,确保指向目标网站的合法页面。
Q2:如何采集需要登录后才能看到的内容?
A:采集登录后内容需配置Cookie:1)在目标网站登录账号,使用浏览器开发者工具(F12)切换到“网络”选项卡,刷新页面,找到登录请求的请求头,复制其中的Cookie值;2)在火车头采集器的“高级设置”中,进入“Cookie管理”,添加新Cookie,将复制的Cookie值粘贴到“Cookie内容”栏,并填写对应的域名(如“.example.com”);3)保存配置后测试采集,确保能抓取到登录后的数据,若Cookie过期,需重新获取并更新。
文章来源网络,作者:运维,如若转载,请注明出处:https://shuyeidc.com/wp/401038.html<