
爬虫技术是自动化获取网站数据的重要手段,其核心在于模拟浏览器行为,解析并提取目标网站的结构化信息,要实现爬虫对网站代码的抓取与分析,需遵循系统化的流程,涉及目标分析、技术选型、代码实现、反爬应对及数据存储等多个环节,以下从技术细节和实践角度展开说明。


目标分析与技术选型
在编写爬虫前,需明确目标网站的结构和数据特征,判断网站是静态页面(HTML直接渲染)还是动态页面(通过JavaScript异步加载数据),这直接影响爬虫的实现策略,静态页面可直接通过HTTP请求获取HTML源码,而动态页面需使用无头浏览器(如Selenium、Playwright)渲染页面后再提取代码,技术选型方面,Python是主流语言,搭配Requests库处理HTTP请求、BeautifulSoup或lxml解析HTML、Scrapy框架构建分布式爬虫,或Selenium模拟用户操作,可根据需求灵活组合。
静态网站代码抓取流程
对于静态网站,核心步骤包括发送请求、解析HTML和提取数据,使用Requests库发送GET请求,通过headers参数模拟浏览器访问(如添加User-Agent避免被识别为爬虫),并设置timeout防止请求超时,获取响应后,通过response.text或response.content获取页面源码。
import requests
url = "https://example.com"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers, timeout=10)
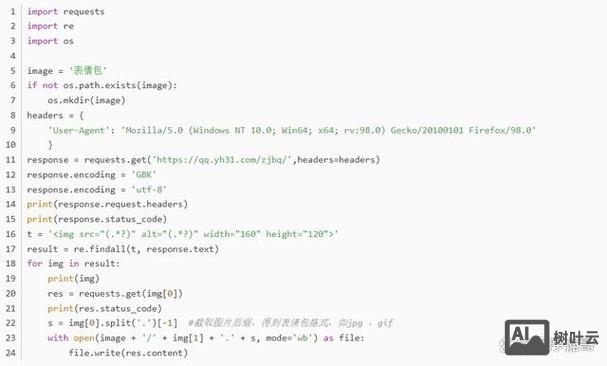
html_code = response.text使用BeautifulSoup解析HTML,通过标签、类名、CSS选择器定位目标元素,提取所有<div class="content">中的文本:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_code, 'html.parser')
contents = soup.find_all('div', class_='content')
for item in contents:
print(item.get_text())动态网站代码抓取
动态网站依赖JavaScript渲染,需使用Selenium等工具控制浏览器,首先下载对应浏览器的WebDriver(如ChromeDriver),并配置Selenium:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("--headless") # 无头模式
driver = webdriver.Chrome(options=options)
driver.get("https://example.com/dynamic-page")
html_code = driver.page_source # 获取渲染后的HTML
driver.quit()获取的HTML代码与静态页面解析方法一致,但需注意动态加载可能存在时间延迟,可通过time.sleep()或显式等待(WebDriverWait)确保元素加载完成。
反爬机制应对
网站通常通过User-Agent检测、IP限制、验证码等手段反爬,应对策略包括:1. User-Agent池:随机切换User-Agent,模拟不同设备访问;2. 代理IP:使用代理IP池(如免费代理或付费服务)避免单一IP被封;3. 请求频率控制:通过time.sleep()随机延迟请求间隔,避免高频触发反爬;4. 验证码处理:简单验证码可通过OCR识别(如pytesseract),复杂验证码需借助第三方平台(如2Captcha),Scrapy框架内置的RandomizedHttpProxyMiddleware和UserAgentMiddleware可简化反爬配置。
数据存储与代码解析
提取的网站代码或数据需持久化存储,常用格式包括CSV、JSON或数据库(如MySQL、MongoDB),使用pandas存储为CSV:
import pandas as pd
data = {"title": ["Title1", "Title2"], "content": ["Content1", "Content2"]}
df = pd.DataFrame(data)
df.to_csv("output.csv", index=False)若需分析网站代码结构(如提取所有链接或标签),可通过正则表达式或BeautifulSoup遍历DOM树,例如提取所有<a>标签的href属性:
links = soup.find_all('a')
for link in links:
print(link.get('href'))相关问答FAQs
Q1: 爬虫如何处理JavaScript渲染的动态内容?
A1: 对于JavaScript渲染的页面,需使用无头浏览器(如Selenium、Playwright)模拟用户操作,先加载页面并等待JS执行完成,再通过page_source获取完整HTML代码,Selenium中可通过WebDriverWait等待特定元素出现,确保数据加载完成后再解析。
Q2: 如何避免爬虫被网站封禁IP?
A2: 可通过以下方法降低被封风险:1. 使用代理IP池,定期更换出口IP;2. 控制请求频率,添加随机延迟(如1-3秒);3. 模拟真实浏览器行为,设置合理的User-Agent和Referer;4. 采用分布式爬虫,通过多节点分散请求压力,遵守网站的robots.txt协议,避免爬取禁止访问的页面。
文章来源网络,作者:管理,如若转载,请注明出处:https://shuyeidc.com/wp/418085.html<