
知识网络构建是一个系统性工程,旨在将零散的知识点通过逻辑关系连接成有机整体,从而提升知识的理解深度、应用灵活性和创新能力,其核心在于“关联”与“结构化”,通过梳理知识间的内在联系,形成可检索、可扩展、可迁移的认知网络,以下从目标设定、数据采集、关系设计、工具选择、可视化呈现及动态优化六个维度,详细阐述知识网络构建的具体方法。
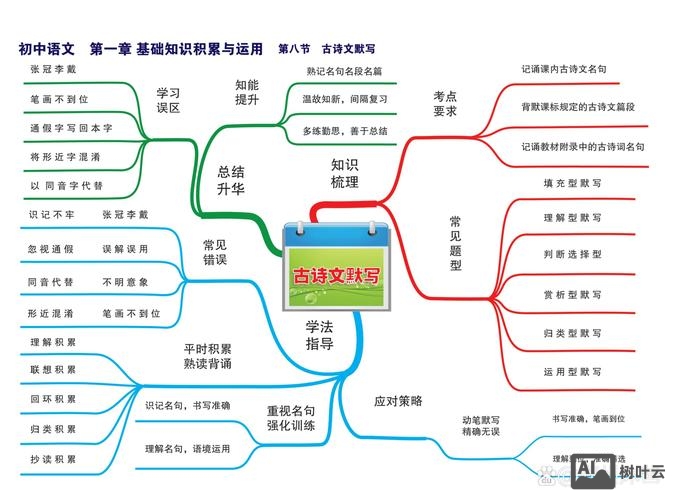

明确构建目标与范围
知识网络构建需以具体目标为导向,避免盲目扩张,目标可分为三类:学习辅助型(如梳理学科知识体系)、研究分析型(如整合领域前沿动态)、业务支撑型(如构建企业知识库),不同目标决定知识范围的选择:学习型需聚焦核心概念与基础理论,研究型需覆盖文献、实验数据及争议观点,业务型则需结合流程、案例与规则,构建“人工智能”知识网络时,学习型可限定在机器学习、深度学习等基础分支,而研究型需纳入Transformer架构、大语言模型等最新进展,需界定边界,避免无限扩展——初期可通过“核心关键词+关联关键词”的方式限定范围,后续再逐步迭代。
多源数据采集与预处理
知识网络的“节点”来源于高质量数据,需通过多渠道采集并标准化处理,数据来源包括:文本类(教材、论文、行业报告、笔记)、结构化数据(数据库、API接口返回的规范数据)、多媒体类(视频、音频的文本转录)、经验类(专家访谈、实践案例),采集后需进行预处理:
- 去重与清洗:剔除重复信息,修正错误表述(如矛盾的定义、过时的数据);
- 结构化提取:从非结构化文本中抽取关键实体(如人名、术语、事件),例如用NLP工具从论文摘要中提取“研究方法”“等要素;
- 标准化命名:统一术语表达(如“神经网络”与“NN”需统一为“神经网络”),避免歧义。
以下为常见数据类型及处理工具示例:
| 数据类型 | 采集渠道 | 预处理工具/方法 |
|---|---|---|
| 学术文献 | 知网、arXiv、Google Scholar | EndNote(去重)、SciSpacy(实体抽取) |
| 行业报告 | 艾瑞咨询、麦肯锡、公司年报 | Python(正则表达式清洗)、Excel(分类) |
| 个人笔记 | Notion、印象笔记、手写稿 | Markdown(格式化)、关键词提取(TF-IDF) |
| 专家经验 | 访谈记录、会议纪要 | 主题建模(LDA)、流程图梳理 |
设计知识关系模型
知识网络的核心是“关系”,需根据目标定义节点间的连接类型,常见关系类型包括:
- 层级关系:表示“包含”或“属于”,如“深度学习→卷积神经网络(CNN)”;
- 因果关系:表示“导致”或“影响”,如“数据量增加→模型性能提升”;
- 依赖关系:表示“基础与延伸”,如“掌握线性代数→理解神经网络原理”;
- 相似关系:表示“概念交叉”,如“支持向量机(SVM)与逻辑回归均用于分类”;
- 时序关系:表示“发展顺序”,如“专家系统(1980s)→机器学习(2000s)→深度学习(2010s)”。
关系设计需遵循“唯一性”与“可解释性”原则,避免冗余连接(如同一对节点不超过2种关系),可通过“关系矩阵”初步梳理:行节点与列节点相交的单元格标注关系类型(如1=层级,2=因果),后续再转化为网络图中的边属性。
选择合适的构建工具
工具选择需结合数据规模、关系复杂度及技术能力,主流工具可分为三类:
- 轻量级可视化工具:适合个人学习与小规模网络,如 XMind(思维导图,支持层级关系)、TheBrain(动态网络,可拖拽节点关联)、Miro(在线协作白板,支持多人实时编辑)。
- 专业网络分析工具:适合研究型与大规模网络,如 Gephi(开源,支持百万级节点布局,可计算网络密度、中心性等指标)、Cytoscape(生物信息领域常用,支持自定义样式与插件)、 Neo4j(图数据库,适合存储动态关系,支持Cypher查询语言)。
- 代码化构建方案:适合需高度定制化的场景,如 Python(NetworkX库)(可编程构建网络,分析拓扑结构)、JavaScript(D3.js)(开发交互式可视化网页)。
构建企业知识库时,可用Neo4j存储“员工-项目-技能”的关系,通过Cypher查询“掌握Python且参与过AI项目的员工”;而个人学习笔记用XMind梳理层级关系后,可导出为Markdown再导入Obsidian(双向链接工具)形成个人知识网络。
可视化与动态优化
知识网络的可视化需兼顾“美观”与“实用”,核心是让关系一目了然,布局算法选择是关键:
- 力导向布局:适合展示复杂关系,节点自动分布,连线长度反映关系强度(如Gephi默认算法);
- 层级布局:适合树状结构,如“学科→分支→知识点”的纵向梳理(如XMind的树形图);
- 环形布局:适合展示对称关系,如“不同算法的优缺点对比”。
可视化后需持续优化:
- 节点精简:合并低频节点(如出现次数<3的次要概念),突出核心节点(通过节点大小或颜色区分);
- 关系增强:对关键关系加粗或标注权重(如“数据量→模型性能”可标注“相关系数0.8”);
- 交互设计:支持点击节点展开子网络、搜索节点路径,提升用户体验(如D3.js实现的缩放、高亮功能)。
动态优化是知识网络的生命力所在:定期更新数据(如每周添加3篇新论文)、调整关系模型(如新发现“联邦学习”与“隐私计算”的依赖关系)、删除过时节点(如已被淘汰的技术)。
应用与迭代
构建知识网络的最终目的是“应用”,需通过具体场景验证其价值,并反向优化结构,常见应用场景包括:
- 知识检索:快速定位关联信息(如查询“Transformer”时,自动展示注意力机制、BERT模型等关联节点);
- 学习路径规划:根据依赖关系生成学习顺序(如“先学Python基础,再学Pandas,最后学机器学习库”);
- 创新发现:通过分析网络中的“桥接节点”(连接不同领域的概念),发现交叉创新点(如“区块链+供应链金融”)。
应用中需收集反馈:用户检索不到信息时,可能是节点缺失或关系未建立;学习路径不合理时,需调整关系权重(如将“数学基础”的依赖权重提高),通过“应用-反馈-优化”的闭环,知识网络将逐步完善。
相关问答FAQs
Q1:知识网络构建与思维导图有何区别?
A:思维导图是树状层级结构,适合线性梳理知识点,关系类型单一(多为“包含”);知识网络是网状结构,可表达多种复杂关系(因果、依赖、相似等),支持动态扩展与交叉分析,思维导图是知识网络的“子集”,适合初步梳理,而知识网络更适合深度整合与创新应用。
Q2:如何避免知识网络变得混乱难以维护?
A:需遵循“三原则”:一是“核心聚焦”,初期限定知识范围(如只覆盖某一学科),避免无限扩张;二是“关系标准化”,提前定义关系类型(如层级、因果)并统一命名,避免歧义;三是“工具分层”,用轻量级工具(如XMind)梳理小范围网络,用专业工具(如Neo4j)存储大规模网络,同时定期备份与迭代,确保结构清晰。
文章来源网络,作者:管理,如若转载,请注明出处:https://shuyeidc.com/wp/446571.html<