
人才招聘网站数据流图是描述该系统内部数据流动、处理过程以及存储结构的可视化工具,能够清晰展现从用户注册到最终招聘完成的完整数据生命周期,以下从外部实体、数据流、数据存储和处理过程四个维度,详细拆解其核心构成与逻辑关系。
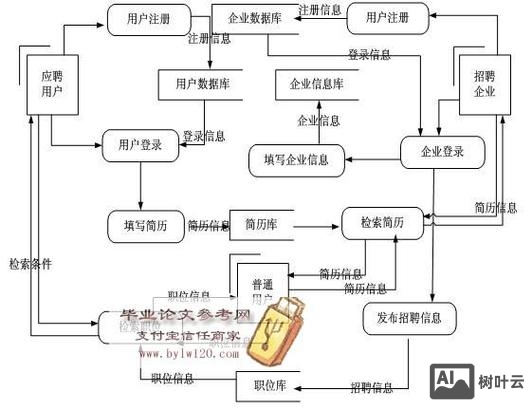

外部实体与数据交互
人才招聘网站涉及五类核心外部实体,各自与系统存在明确的数据输入输出关系:
- 求职者:作为核心用户群体,其行为数据包括注册时提交的个人信息(姓名、联系方式、学历、工作经历等)、简历投递记录(目标岗位、附件简历、求职信)、职位搜索历史(关键词、筛选条件)以及面试反馈(接受/拒绝offer、评价),系统需向求职者推送职位推荐、申请状态更新(如“简历被查看”“进入面试”)和平台通知。
- 企业招聘方:需提交企业认证信息(营业执照、组织机构代码)、发布的职位需求(岗位名称、职责、薪资范围、任职要求)、简历筛选结果(通过/不通过标记)以及面试安排(时间、形式),系统则提供人才库检索功能(按技能、经验等维度筛选)、简历下载权限和招聘数据统计(如岗位投递量、转化率)。
- 系统管理员:负责维护基础数据,包括行业分类、职位类别、城市字典等枚举值,以及用户权限管理(如企业账号审核、求职者账号封禁),同时监控异常数据(如重复注册、虚假信息)并执行处理操作。
- 第三方服务:如短信/邮件网关(用于发送验证码、通知)、支付接口(企业购买会员服务)、第三方简历解析工具(解析非结构化简历文本)等,需与系统进行标准化数据交换。
核心数据流与处理过程
数据流图通过“处理过程”将数据流转化为有价值的信息,以下是关键处理节点的逻辑说明:
| 处理过程编号 | 处理名称 | 输入数据流 | 处理逻辑 | 输出数据流 |
|---|---|---|---|---|
| 1 | 用户注册 | 求职者/企业提交的注册信息 | 验证信息完整性(手机号格式、邮箱格式)、去重检查(手机号/邮箱是否已存在) | 注册成功通知、用户ID |
| 2 | 简历管理 | 求职者上传的简历文件、手动填写信息 | 调用第三方解析工具提取文本内容,结构化存储(技能、工作年限、学历等字段) | 结构化简历数据、简历解析报告 |
| 1 | 职位发布 | 企业提交的职位描述、薪资范围等 | 关键词提取(如“Java”“5年以上经验”),匹配行业分类,生成职位ID | 可发布的职位信息、职位发布成功通知 |
| 2 | 职位搜索与推荐 | 求职者搜索关键词、历史浏览记录 | 基于协同过滤算法(相似用户行为)+ 内容匹配(技能关键词权重),排序生成推荐列表 | 匹配的职位列表、推荐理由(如“80%匹配度”) |
| 1 | 简历投递 | 求职者选择的职位ID、简历ID | 检查投递权限(如是否已投递过)、生成投递记录(时间戳、状态) | 投递成功确认、企业端新申请提醒 |
| 2 | 简历筛选 | HR设置的筛选条件(学历、经验等) | 遍历投递简历库,按条件过滤(如“学历≥本科”“经验3-5年”),标记筛选结果 | 筛选通过的简历列表、筛选统计报告 |
| 1 | 面试安排 | HR确认的面试时间、求职者联系方式 | 生成面试邀请(含会议链接),通过短信/邮件发送,更新申请状态为“面试中” | 面试邀请记录、状态变更通知 |
| 1 | 数据统计分析 | 各模块产生的操作日志(注册、投递等) | 按日/周/月聚合数据(如新增求职者数、岗位平均薪资、投递转化率) | 可视化报表(Dashboard)、数据导出文件 |
数据存储结构
数据流图中的“数据存储”是持久化数据的载体,主要分为三类:
- 用户基础数据存储:包括求职者信息表(user_info,字段:user_id, name, phone, email, register_time)、企业信息表(company_info,字段:company_id, name, license_num, contact_person),通过user_id/company_id作为外键关联其他表。
- 业务核心数据存储:职位信息表(job_post,字段:job_id, company_id, job_title, salary_min, salary_max, requirement, publish_time)、简历库表(resume,字段:resume_id, user_id, skills, work_experience, education)、投递记录表(application,字段:application_id, job_id, user_id, apply_time, status(待处理/已查看/面试中/已拒绝)),投递记录表通过job_id和user_id关联职位表与用户表,实现“谁投了什么岗位”的追溯。
- 日志与配置数据存储:操作日志表(log,字段:log_id, user_id, action_type, ip, timestamp)、系统配置表(config,字段:config_key, config_value,如“简历解析API地址”“短信模板ID”),用于系统审计与功能配置管理。
数据流闭环与异常处理
完整的数据流需形成闭环,求职者搜索职位(输入关键词)→ 系统返回匹配列表(数据处理)→ 求职者投递简历(用户操作)→ 企业筛选简历(数据处理)→ 安排面试(状态变更)→ 更新求职者端申请状态(数据输出),异常处理则贯穿始终,如简历投递时需检查企业是否已暂停招聘(数据校验),若异常则终止流程并返回错误提示;数据统计时对空值(如未填写薪资的职位)进行默认值填充或标记,确保报表准确性。
相关问答FAQs
Q1:人才招聘网站数据流图中,“职位推荐”处理过程的数据来源有哪些?
A1:职位推荐的数据来源主要包括三类:一是求职者主动行为数据(搜索关键词、浏览记录、投递记录),用于构建用户画像;二是职位静态属性数据(技能要求、行业类别、薪资范围),用于内容匹配;三是协同过滤数据(相似求职者的投递偏好),投递A岗位的用户也常投递B岗位”,系统通过融合这三类数据,计算职位与用户的匹配度,最终生成推荐列表。
Q2:如何确保数据流图中“简历筛选”处理过程的准确性和效率?
A2:准确性方面,采用多级校验机制:一是企业HR设置的筛选条件需通过系统规则引擎校验(如“学历”字段仅允许选择枚举值中的选项);二是简历解析时对关键信息(如“工作年限”)进行结构化提取并标准化(统一为“年”为单位),避免文本歧义;三是筛选结果支持人工复核,HR可调整权重或添加自定义条件,效率方面,通过建立倒排索引(如按“技能”字段建立索引,快速定位含“Python”的简历)和缓存热门筛选条件的结果,减少实时计算量,确保大规模简历筛选时的响应速度。
文章来源网络,作者:运维,如若转载,请注明出处:https://shuyeidc.com/wp/471396.html<