
制作一个数据监控网站需要综合运用前端开发、后端开发、数据库管理和数据可视化等技术,核心目标是实时或定期采集、处理、展示关键数据指标,帮助用户快速掌握业务状态或系统运行情况,以下从需求分析、技术选型、功能模块开发、部署维护等方面详细说明制作流程。
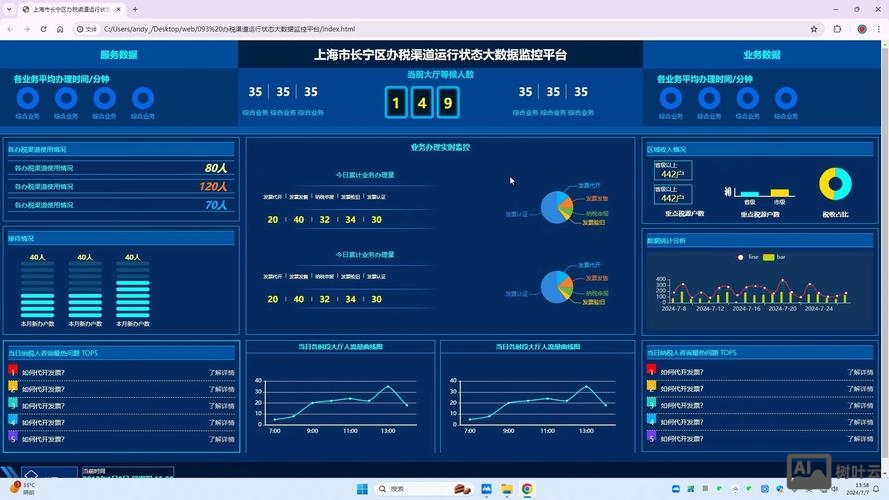

需求分析与规划
在开发前需明确监控目标,这是系统设计的核心,不同场景的监控需求差异较大:
- 业务监控:如电商平台的日活跃用户(DAU)、订单转化率、销售额等关键业务指标;
- 系统监控:如服务器CPU使用率、内存占用、网络带宽、响应时间等性能指标;
- 日志监控:如应用错误日志、用户访问日志的异常统计;
- 自定义监控:如特定API接口的调用成功率、数据库查询效率等。
需与需求方确认监控指标、数据更新频率(实时/分钟级/小时级)、展示形式(图表/表格/阈值告警)、用户权限(管理员/普通用户)等细节,并梳理数据来源(如数据库、API接口、日志文件、第三方平台等)。
技术选型
根据需求复杂度和团队技术栈选择合适的技术组合,以下为常见方案:
| 模块 | 技术选型示例 | 说明 |
|---|---|---|
| 前端框架 | React/Vue.js + ECharts/D3.js/Chart.js | React/Vue用于构建交互式界面,ECharts等图表库实现数据可视化,支持折线图、柱状图、饼图等 |
| 后端框架 | Node.js(Express/Koa) / Python(Django/Flask) / Java(Spring Boot) | 根据团队熟悉度选择,需支持API开发、定时任务、数据处理逻辑 |
| 数据库 | MySQL/PostgreSQL(关系型,存储结构化指标数据)+ Redis(缓存,存储实时数据) | 关系型数据库存储历史数据,Redis缓存高频访问数据,降低数据库压力 |
| 数据采集 | Python脚本(requests/BeautifulSoup)+ 定时任务(Celery/Airflow)+ 第三方SDK | 若数据来自API,可通过脚本定时请求;若来自日志,可使用Filebeat/Logstash采集 |
| 部署与运维 | Docker容器化 + Nginx反向代理 + PM2/Supervisor进程管理 + 云服务器(AWS/阿里云) | 容器化部署简化环境配置,Nginx负责负载均衡和静态资源服务 |
| 告警通知 | 邮件/企业微信/钉钉API + 告警规则引擎(如Prometheus Alertmanager) | 当指标超过阈值时,通过API发送告警信息,需支持规则自定义(如连续3次超过阈值告警) |
功能模块开发
数据采集模块
根据数据来源设计采集逻辑:
- API接口采集:若目标平台提供API(如电商平台的订单API),使用Python的
requests库或前端fetch定时请求接口,解析JSON数据并提取关键指标,需注意API限流问题,可通过缓存或降低请求频率规避。 - 数据库直连:通过后端框架连接数据库(如MySQL的
pymysql库),编写SQL语句查询指标数据(如SELECT COUNT(*) FROM orders WHERE date='2024-01-01'),适合结构化数据采集。 - 日志文件解析:若数据存储在日志文件中,可使用正则表达式或日志解析库(如Python的
loguru)提取关键信息,例如从Nginx访问日志中提取状态码和响应时间。
采集后的数据需进行清洗(去除空值、异常值)、格式转换(统一时间格式、数值单位),然后存储到数据库或缓存中。
数据处理与存储模块
- 实时数据处理:对于高频更新的数据(如服务器CPU使用率),可采用Redis存储最新值,并通过WebSocket推送给前端,实现实时展示。
- 历史数据存储:将每日/每小时聚合后的指标存储到MySQL等关系型数据库,按时间分表(如按月建表)提升查询效率,创建表
daily_metrics(date, metric_name, value, unit),存储每日DAU、订单量等数据。 - 数据聚合计算:对于需要统计的指标(如近7日平均DAU),可在后端使用SQL的
AVG()函数或通过定时任务预计算,减少前端实时计算的压力。
前端展示模块
前端需实现数据可视化、交互功能和用户权限控制:
- 图表组件:使用ECharts绘制折线图展示指标趋势(如近30日销售额变化),饼图展示占比(如各品类订单占比),表格展示明细数据(如实时订单列表),需配置图表的响应式布局,适配不同屏幕尺寸。
- 实时更新:通过WebSocket连接后端,当数据更新时前端自动刷新图表(如每5秒更新一次服务器CPU使用率),若使用轮询,可通过
setInterval定时请求API获取最新数据。 - 筛选与交互:添加日期选择器、指标下拉框等筛选组件,支持用户按时间范围、指标类型筛选数据,选择“近7天”和“订单转化率”后,图表动态更新对应数据。
- 权限控制:通过前端路由(如React Router)和后端接口权限(如JWT token)区分用户权限,管理员可查看所有指标和配置告警,普通用户仅查看基础数据。
告警模块
当指标超过预设阈值时触发告警,需实现以下功能:
- 规则配置:在后端提供告警规则管理界面,支持用户设置指标名称、阈值(如CPU使用率>80%)、持续时间(如连续5分钟)、通知方式(邮件/企业微信)。
- 触发机制:通过定时任务(如Python的
APScheduler)每分钟检查指标数据,若满足规则则触发告警,查询Redis中的最新CPU使用率,若超过阈值则记录告警日志并发送通知。 - 通知发送:调用企业微信机器人API或邮件服务(如Python的
smtplib),发送告警信息至指定群组或邮箱,内容需包含指标名称、当前值、阈值和触发时间。
部署与维护
- 容器化部署:将前端、后端、数据库分别打包为Docker镜像,使用
docker-compose编排服务,确保环境一致性,前端通过Nginx镜像部署,后端通过Node.js镜像运行,数据库使用MySQL官方镜像。 - 性能优化:对高频查询的API添加Redis缓存(如缓存近7日DAU数据),减少数据库压力;使用CDN加速前端静态资源加载;对数据库添加索引(如
daily_metrics表的date字段索引),提升查询效率。 - 监控与日志:使用Prometheus+Grafana监控自身系统状态(如服务器负载、API响应时间),并通过ELK(Elasticsearch+Logstash+Kibana)收集应用日志,便于排查问题。
- 迭代更新:根据用户反馈新增监控指标、优化图表展示或调整告警规则,定期更新代码并部署新版本。
相关问答FAQs
Q1: 数据监控网站如何保证实时性?
A1: 实时性可通过以下方式实现:①高频数据采集(如每秒采集服务器指标)和实时传输(WebSocket协议);②使用Redis缓存最新数据,减少数据库查询延迟;③前端采用实时渲染技术(如ECharts的realtime模式),数据更新时自动刷新图表,同时需权衡实时性与资源消耗,避免过度采集导致服务器负载过高。
Q2: 如何处理监控数据量过大导致的性能问题?
A2: 可从存储、查询、计算三方面优化:①存储层面,采用时间序列数据库(如InfluxDB)替代关系型数据库,更适合存储时序数据;或对历史数据按时间分表(如按月分表),定期归档旧数据。②查询层面,添加数据库索引、使用缓存(Redis)存储高频查询结果,避免全表扫描。③计算层面,通过定时任务预计算聚合指标(如日均值、月环比),减少实时计算量,可对数据进行采样(如每10秒记录一次原始数据,聚合时保留均值),降低数据存储压力。
文章来源网络,作者:运维,如若转载,请注明出处:https://shuyeidc.com/wp/479544.html<