
运行Hadoop命令是大数据处理中的核心操作,涵盖了从集群管理到数据处理的多个场景,Hadoop基于HDFS(分布式文件系统)和YARN(资源管理器)构建,命令行工具(如hadoop fs、hdfs dfs、yarn等)是用户与集群交互的主要方式,以下从基础命令、高级操作及常见场景展开说明,帮助用户全面掌握Hadoop命令的使用方法。

(图片来源网络,侵删)
基础文件操作命令
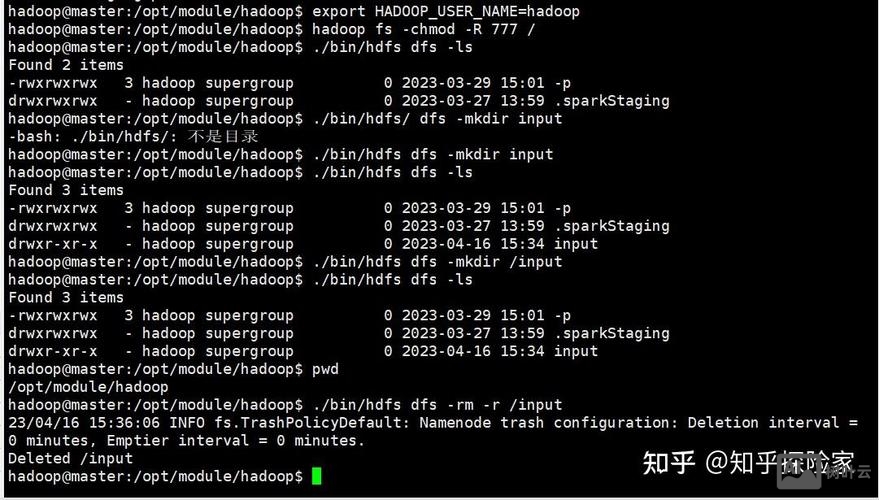
Hadoop的文件操作命令与Linux的Shell命令类似,但针对分布式环境进行了优化,最常用的命令是hadoop fs或hdfs dfs,两者功能基本一致,后者更明确指向HDFS。
文件上传与下载
- 上传本地文件到HDFS:
hadoop fs -put /local/path /hdfs/pathhadoop fs -put input.txt /user/hadoop/input - 下载HDFS文件到本地:
hadoop fs -get /hdfs/path /local/pathhadoop fs -get /user/hadoop/output/result.txt ./output - 追加本地文件到HDFS:
hadoop fs -appendToFile local.txt /hdfs/target.txt
- 上传本地文件到HDFS:
目录与文件管理
- 创建目录:
hadoop fs -mkdir /user/hadoop/output - 列出文件:
hadoop fs -ls /user/hadoop(支持-R递归列出) - 删除文件或目录:
hadoop fs -rm /user/hadoop/input.txt(-rm -r递归删除目录) - 移动或重命名:
hadoop fs -mv /old/path /new/path
- 创建目录:
查看文件内容
 (图片来源网络,侵删)
(图片来源网络,侵删)- 查看小文件:
hadoop fs -cat /user/hadoop/input.txt - 分页查看:
hadoop fs -cat /largefile.txt | more - 显示文件末尾:
hadoop fs -tail /user/hadoop/output/part-m-00000
- 查看小文件:
高级数据处理命令
Hadoop支持通过MapReduce或Spark进行分布式计算,命令需结合YARN资源管理器执行。
运行MapReduce作业
- 提交作业:
hadoop jar wordcount.jar WordCount /input /output
其中wordcount.jar是包含主类的JAR包,WordCount为类名,后两个参数分别为输入输出路径。 - 查看作业状态:
yarn application -list -appStates ALL - 杀死作业:
yarn application -kill <application_id>
- 提交作业:
HDFS磁盘与性能管理
- 检查磁盘使用情况:
hdfs dfsadmin -report - 平衡集群数据:
hadoop balancer -threshold 5(阈值默认为10,数值越小平衡越严格) - 查看文件块信息:
hadoop fsck /user/hadoop/input -files -blocks -locations
- 检查磁盘使用情况:
集群管理与监控命令
节点状态检查
 (图片来源网络,侵删)
(图片来源网络,侵删)- 查活节点:
hadoop dfsadmin -report - 进入安全模式:
hadoop dfsadmin -safemode enter(维护时使用,退出用leave)
- 查活节点:
日志与调试
- 查看任务日志:
yarn logs -applicationId <application_id> - 查看Hadoop守护进程日志:
tail -f $HADOOP_HOME/logs/hadoop-<user>-namenode-<hostname>.log
- 查看任务日志:
常见操作场景示例
以下表格总结了典型场景的命令组合:
| 场景 | 命令示例 |
|---|---|
| 批量上传文件 | hadoop fs -put *.txt /user/hadoop/batch_input |
| 统计目录大小 | hadoop fs -du -s -h /user/hadoop |
| 清理输出目录 | hadoop fs -rm -r /user/hadoop/output && hadoop jar job.jar input output |
| 检查文件完整性 | hadoop fsck /path/to/file -includeLocations -files |
相关问答FAQs
Q1: 提交MapReduce作业时提示“Permission denied”,如何解决?
A: 通常是由于HDFS目录权限不足导致,可通过以下命令修复:
hadoop fs -chown -R <hadoop_user>:<hadoop_group> /user/hadoop hadoop fs -chmod -R 755 /user/hadoop
其中<hadoop_user>为Hadoop运行用户,确保该用户对相关目录有读写权限。
Q2: 如何查看MapReduce作业的详细执行进度?
A: 可通过以下方式获取实时进度:
- 使用Web UI:访问YARN ResourceManager的Web界面(默认地址
http://<namenode>:8088),点击对应作业查看进度。 - 命令行查看:
yarn application -status <application_id>显示作业状态,或通过mapred job -counter <job_id> <group> <counter>查看具体计数器。
掌握Hadoop命令需要结合实践,建议在测试环境中反复操作,熟悉命令参数与集群响应机制,以高效解决实际工作中的问题。
文章来源网络,作者:运维,如若转载,请注明出处:https://shuyeidc.com/wp/379290.html<