
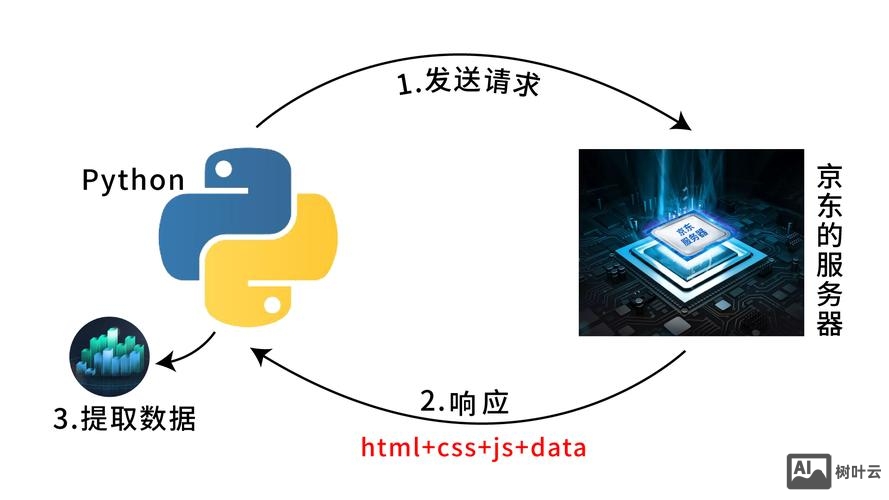
的基础过程,类似于人类在图书馆中逐页翻阅书籍以记录信息,这一过程由称为“爬虫”(Spider或Crawler)的自动化程序执行,通过系统性地发现、抓取和存储网页数据,为后续的索引和检索提供原始素材,爬行的效率和质量直接影响搜索引擎的结果覆盖范围和更新速度,因此理解其运作机制对网站优化和内容获取至关重要。


爬行的基础原理与目标
搜索引擎爬行的核心目标是“发现并获取互联网上的可用网页”,为实现这一目标,爬虫需要解决两个关键问题:从哪里开始爬行以及如何继续发现新网页,初始阶段,爬虫通常依赖一组人工维护的“种子URL列表”(Seed URLs),这些列表包含高价值页面(如知名门户网站、政府网站、教育机构主页等),具有较高稳定性和权威性,随后,爬虫通过解析这些页面的内容,提取其中的超链接(URLs),形成新的待抓取队列,逐步扩展覆盖范围。
在爬行过程中,爬虫需遵循一系列规则,避免重复抓取、无效页面或恶意内容,通过检查HTTP状态码(如200表示成功、404表示页面不存在)判断页面有效性;通过分析页面的robots.txt文件(搜索引擎爬虫排除协议)确定是否允许抓取;通过计算URL的“优先级”或“重要性”决定抓取顺序,确保高价值页面优先被处理。
爬行的核心流程与技术实现
爬行的具体流程可分为“发现-抓取-解析-存储”四个阶段,每个阶段依赖不同的技术和算法优化效率。
URL发现与队列管理
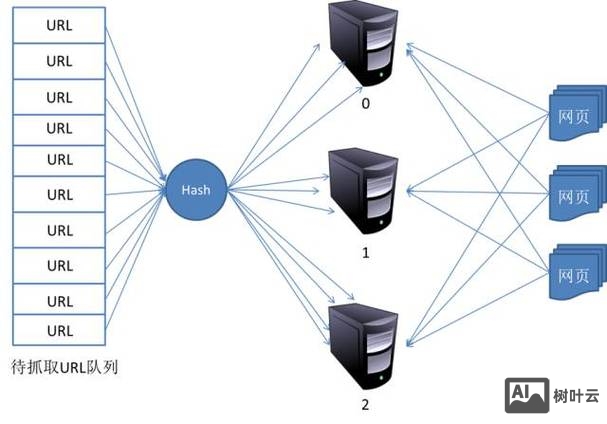
爬虫的“起点”是种子URL,但后续页面的发现主要依赖超链接解析,当爬虫抓取一个页面后,会解析其中的HTML代码,提取<a>标签中的href属性值(即目标URL),并将其加入“待抓取URL队列”(URL Frontier),为避免重复和冗余,队列管理需解决两个问题:URL去重和优先级排序。
- URL去重:通过哈希算法(如MD5、SHA-1)对URL进行编码,建立已抓取URL的指纹库,避免重复处理相同页面。
- 优先级排序:搜索引擎会根据页面的权重(如域名权威度、外链数量、更新频率等)分配优先级,高优先级页面(如新闻首页、百科词条)被优先抓取,Google的PageRank算法和百度的权重体系都会影响URL在队列中的位置。
爬虫还会通过“站点地图”(Sitemap)文件高效发现页面,网站管理员可通过XML格式的Sitemap主动向搜索引擎提交页面列表,帮助爬虫更全面地覆盖网站内容,尤其适合动态生成或深层嵌套的页面。
页面抓取与网络通信
发现URL后,爬虫需通过HTTP/HTTPS协议向目标服务器发送请求,获取页面内容,这一过程涉及网络通信的多个环节,包括DNS解析(将域名转换为IP地址)、建立TCP连接、发送HTTP请求(GET/POST方法)以及接收响应数据。
为提高抓取效率,现代爬虫采用分布式架构,由成百上千台服务器组成爬虫集群,并行处理多个URL请求,通过“ polite crawling”(礼貌抓取)策略控制请求频率,避免对目标服务器造成过大压力(如设置每秒最大请求数、遵守robots.txt中的抓取延迟指令)。
页面解析与内容提取
抓取到的原始页面通常是HTML、CSS、JavaScript等代码,需进一步解析提取有效内容,爬虫会重点关注以下元素:
- (
<title>)、正文(<p>、<div>等标签内的文字)、关键词(<meta name="keywords">)等; - 链接结构:用于发现新URL,同时分析页面的内部链接关系(如网站导航、相关文章推荐);
- 元数据:如
<meta name="description">(页面描述)、<link rel="canonical">(规范URL)等,辅助理解页面主题和权重。
对于JavaScript渲染的页面(如单页应用SPA),传统爬虫可能无法直接获取动态内容,为此,现代搜索引擎(如Google的Chrome Headless、百度的BaiduSpider)已集成浏览器内核,支持执行JavaScript代码,确保抓取到用户最终看到的页面内容。
内容存储与队列更新 会被存储到搜索引擎的数据库中,形成原始索引库,提取的新URL会被加入待抓取队列,继续下一轮爬行,这一过程循环进行,直到满足停止条件(如队列中的URL被全部处理、达到预设的抓取深度或时间限制)。
影响爬行效率的关键因素
爬行的效率受多种因素影响,包括爬虫自身的技术能力、网站的结构与配置,以及互联网环境的复杂性。
网站的技术配置
robots.txt文件:位于网站根目录,通过指令(如Disallow:禁止抓取特定目录,Allow:允许抓取例外)控制爬虫行为,若配置错误(如误封重要页面),可能导致内容无法被索引。- 服务器性能与响应速度:服务器过载、响应缓慢(如加载时间超过3秒)会导致爬虫超时或放弃抓取,影响页面收录。
- URL结构:简洁、规范的URL(如
https://example.com/article/123)便于爬虫理解和索引,而动态参数过多(如?id=123&cat=456)可能导致重复内容问题。
质量
- 原创性与价值:原创、高质量的内容更易被爬虫优先抓取,而低质内容(如采集页、广告页)可能被降低抓取频率。
- 更新频率:定期更新的页面(如新闻博客、百科词条)会被爬虫更频繁地访问,以获取最新内容。
- 内部链接结构:清晰的内部链接(如分类目录、相关文章推荐)帮助爬虫发现深层页面,而孤立页面(无外部链接指向)则可能被忽略。
搜索引擎的算法策略
- 爬虫预算(Crawl Budget):搜索引擎为每个网站分配的每日抓取资源(如抓取页面数、带宽),高权重网站的预算更高,能被更全面地抓取。
- 去重机制高度重复的页面(如转载文章、打印版本),爬虫可能只保留一个权威版本,忽略其他副本。
相关问答FAQs
Q1: 为什么我的网站页面没有被搜索引擎爬行?
A: 可能的原因包括:(1)网站未提交到搜索引擎平台(如百度搜索资源平台、Google Search Console);(2)robots.txt文件误封了页面目录;(3)服务器响应过慢或频繁宕机,导致爬虫超时;(4)页面无外部链接指向,处于“孤立状态”;(5)页面内容质量低(如大量广告、无实质内容),建议检查网站配置、提交sitemap、提升服务器性能,并增加高质量内部链接。
Q2: 如何提高搜索引擎爬虫对我网站的抓取效率?
A: 可采取以下措施:(1)生成并提交sitemap.xml,主动告知搜索引擎页面结构;(2)优化robots.txt,确保重要目录未被禁止抓取;(3)提升网站加载速度(如压缩图片、启用CDN);(4)定期更新原创内容,增加爬虫访问频率;(5)建立清晰的内部链接体系,帮助爬虫发现深层页面;(6)通过社交媒体、外部平台为网站引流,增加外部链接权重。
文章来源网络,作者:管理,如若转载,请注明出处:https://shuyeidc.com/wp/437556.html<