
在C语言开发中,命令行乱码是一个常见且令人困扰的问题,尤其在Windows系统上表现得更为突出,乱码的本质是字符编码的不匹配,即程序内部使用的编码与命令行终端显示的编码不一致,要解决这个问题,首先需要理解字符编码的基本原理,然后针对不同场景采取相应的措施。

字符编码是将字符集中的字符转换为计算机可以处理的二进制数据的规则,常见的编码包括ASCII、GBK、GB2312、UTF-8等,ASCII编码只能表示英文字符,而GBK和GB2312是中国国家标准编码,主要用于表示中文字符,UTF-8是一种Unicode的实现方式,它兼容ASCII,可以表示世界上几乎所有的字符,是目前互联网上最常用的编码,在Windows系统中,命令行终端(CMD)默认使用的编码是GBK(中文版Windows),而许多现代开发工具和程序源代码可能采用UTF-8编码,这就导致了当UTF-8编码的输出流被GBK的终端读取时,就会出现乱码。
解决C语言命令行乱码问题,可以从以下几个方面入手:
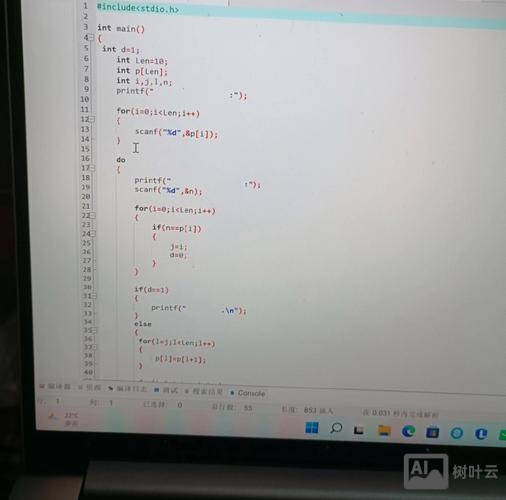
对于简单的控制台程序输出乱码,最直接的方法是修改程序代码,使其输出符合终端的编码要求,如果终端使用GBK,那么程序在输出中文时就应该使用GBK编码,在C语言中,可以使用setlocale函数来设置程序的本地化环境,从而影响字符串的输入输出函数的行为,在程序开头加入setlocale(LC_ALL, "chs");或setlocale(LC_ALL, "Chinese_Simplified.936");,936″是GBK编码在Windows系统中的代码页编号,这样,像printf这样的函数就会按照GBK编码来处理字符串,从而在中文版Windows的CMD中正确显示中文,需要注意的是,setlocale函数必须在使用任何本地化敏感的输入输出函数之前调用,并且它只影响当前程序的运行环境,不会改变终端本身的编码。
如果希望程序始终使用UTF-8编码,并且能够在支持UTF-8的终端中正确显示,那么可以考虑修改终端的编码设置,在Windows 10及更高版本中,微软已经对命令行终端进行了改进,支持UTF-8编码,用户可以通过以下步骤将CMD的代码页设置为UTF-8:打开CMD窗口,右键点击标题栏,选择“属性”,在“选项”标签页中找到“当前代码页”选项,将其更改为“UTF-8”(代码页65001),设置完成后,新打开的CMD窗口就会使用UTF-8编码,如果C程序在输出前调用了setlocale(LC_ALL, "C.UTF-8");或setlocale(LC_ALL, "en_US.utf8");,并且确保源代码文件本身也是以UTF-8编码保存且没有BOM(字节顺序标记),那么程序输出的中文就能正确显示,这种方法的好处是程序代码具有更好的可移植性,不受终端默认编码的限制,但缺点是需要用户手动修改终端设置,且在旧版本Windows上可能不可行。
第三种情况是涉及文件读写时的乱码,当程序以文本模式("r", "w"等)打开文件时,C标准库会进行隐式的编码转换,在Windows上,如果程序使用GBK编码运行,以文本模式读取一个UTF-8编码的文件,或者在程序中使用UTF-8编码写入文件,然后以GBK编码的文本编辑器打开,都会出现乱码,为了避免这种情况,应该以二进制模式("rb", "wb"等)打开文件,然后手动处理编码转换,可以使用第三方库如ICU(International Components for Unicode)或libiconv来进行不同编码之间的转换,在读取文件时,先将文件内容读入缓冲区,然后从UTF-8转换为程序内部使用的编码(如GBK);写入文件时,则进行相反的转换,这种方法虽然增加了编程的复杂性,但能够确保文件数据的正确性,避免编码转换带来的问题。
第四种情况是在重定向输入输出时的乱码,当将程序的输出重定向到文件或另一个程序时,如果重定向目标的编码与程序输出的编码不一致,也会产生乱码,一个使用GBK编码输出的程序,如果将其输出重定向到一个期望UTF-8编码的文本文件中,那么文件内容就会是乱码,解决这个问题的方法与前面类似,要么确保重定向目标的编码与程序一致,要么在程序中进行编码转换后再输出,在Windows系统中,可以使用chcp命令临时改变当前CMD窗口的代码页,例如chcp 65001将代码页设置为UTF-8,chcp 936设置为GBK,在批处理脚本中,可以在运行程序前先执行chcp命令来调整环境。
除了以上针对具体场景的解决方案,还有一些通用的最佳实践可以避免乱码问题的发生,首先是统一编码规范,在整个项目中,从源代码文件编码、程序内部编码到终端编码,都应尽量保持一致,推荐使用UTF-8作为源代码文件的编码,并在编译器设置中明确指定,例如在GCC中使用-finput-charset=utf-8 -fexec-charset=gbk(如果目标终端是GBK)或-finput-charset=utf-8 -fexec-charset=utf-8(如果终端支持UTF-8),其次是使用合适的编辑器和编译器,确保它们能够正确处理所选的编码,并且不会在保存文件时添加不必要的BOM标记,因为BOM有时也会在某些情况下导致问题,最后是进行充分的测试,在不同的操作系统环境和终端设置下测试程序的输入输出,确保编码转换的正确性。
为了更直观地展示不同编码之间的转换关系和解决方法,可以参考下表:
| 场景描述 | 程序编码 | 终端/文件编码 | 解决方法 |
|---|---|---|---|
| 程序输出中文到CMD(中文版Windows) | UTF-8 | GBK | 程序中使用setlocale(LC_ALL, "chs");将终端代码页设为GBK( chcp 936) |
| 程序输出中文到CMD(Windows 10+) | UTF-8 | UTF-8 | 程序中使用setlocale(LC_ALL, "C.UTF-8");将终端代码页设为UTF-8( chcp 65001) |
| 程序读写UTF-8编码文件 | GBK | UTF-8(文件) | 以二进制模式打开文件("rb", "wb")使用libiconv等库进行编码转换 |
| 程序输出重定向到文件 | GBK | UTF-8(文件) | 在程序中将输出转换为UTF-8后再写入 或确保重定向目标文件使用GBK编码 |
C语言命令行乱码问题的根源在于编码不一致,解决的关键在于识别并统一程序、终端和文件之间的编码,通过合理设置本地化环境、修改终端编码、采用二进制模式读写文件以及使用专业的编码转换库,可以有效避免和解决乱码问题,确保程序在不同环境下都能正确处理和显示文本信息,在实际开发中,养成良好的编码习惯,尽早规划和统一编码标准,是预防乱码问题的最有效手段。
相关问答FAQs
问题1:为什么在C语言中使用setlocale(LC_ALL, "UTF-8");在Windows CMD中仍然无法解决中文乱码问题?
解答:在Windows CMD中,即使程序内部通过setlocale(LC_ALL, "UTF-8");设置了UTF-8本地化环境,也可能仍然出现乱码,这是因为Windows CMD的默认代码页是GBK(936),它可能不完全支持setlocale函数对UTF-8的设置。setlocale函数的行为依赖于操作系统的本地化支持,而旧版Windows的C运行时库对UTF-8的支持有限,更可靠的方法是先通过chcp 65001命令将CMD的代码页切换到UTF-8,然后再运行程序,或者在程序中结合使用setlocale和确保终端编码为UTF-8,还需要确保源代码文件本身是以UTF-8编码保存且没有BOM,并且编译器选项也正确处理了UTF-8编码。
问题2:在Linux终端中运行C程序时出现中文乱码,应该如何排查和解决?
解答:在Linux终端中出现中文乱码,通常是由于终端编码与程序输出编码不一致导致的,可以使用locale命令查看当前终端的locale设置,特别是LANG和LC_CTYPE环境变量,它们决定了终端的默认编码,常见的Linux终端编码为UTF-8,如果locale设置为en_US.UTF-8,则终端期望接收UTF-8编码的字符,C程序应该使用setlocale(LC_ALL, "en_US.UTF-8");或setlocale(LC_ALL, "C.UTF-8");来确保字符串函数按UTF-8处理,如果locale设置为类似zh_CN.GBK,则终端使用GBK编码,程序也应相应调整,检查源代码文件的编码,确保是UTF-8,确认终端本身是否支持UTF-8显示,可以通过在终端中输入测试中文字符来验证,如果问题依旧,可能是终端模拟器的配置问题,可以尝试更换终端模拟器(如从GNOME Terminal切换到Konsole)或修改其编码设置。
文章来源网络,作者:管理,如若转载,请注明出处:https://shuyeidc.com/wp/457682.html<