
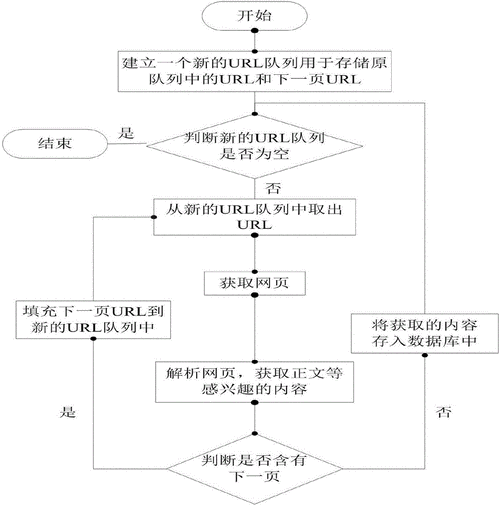
在Django框架中运行爬虫是一个常见的需求,通常需要将爬虫逻辑与Django的Web功能结合,例如将爬取的数据存储到Django的数据库中,或者通过Django的视图和模板展示爬取结果,以下是详细的实现步骤和注意事项,帮助你在Django项目中高效地运行爬虫。
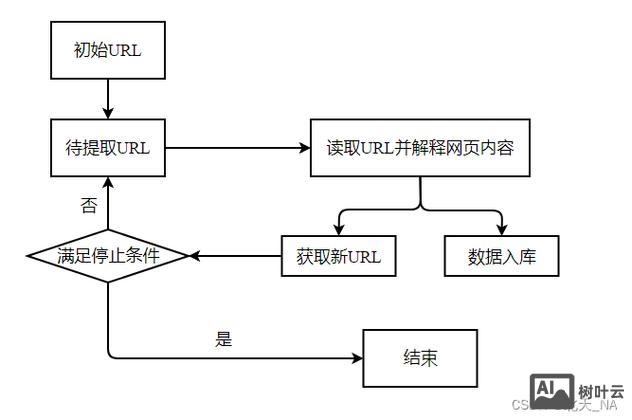

环境准备与项目结构
在开始之前,确保你已经安装了Python、Django以及爬虫所需的库(如Requests、Scrapy、BeautifulSoup等),可以通过以下命令安装必要的依赖:
pip install django requests scrapy beautifulsoup4
创建一个Django项目并应用:
django-admin startproject spider_project cd spider_project python manage.py startapp spider_app
在spider_app目录下,可以创建一个spiders文件夹用于存放爬虫代码,
spider_project/
├── spider_app/
│ ├── spiders/
│ │ └── __init__.py
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── spider_project/
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
└── manage.py定义爬虫逻辑
1 使用Requests + BeautifulSoup
如果爬虫逻辑较为简单,可以直接在Django的视图函数或自定义管理命令中实现,在spider_app/spiders/目录下创建一个simple_spider.py文件:
import requests
from bs4 import BeautifulSoup
from spider_app.models import Article # 假设已定义Article模型
def scrape_articles():
url = "https://example.com/news"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
articles = soup.find_all('div', class_='article')
for article in articles:
title = article.find('h2').text
content = article.find('p').text
Article.objects.create(title=title, content=content)2 使用Scrapy框架
对于复杂的爬虫项目,推荐使用Scrapy,首先安装Scrapy并创建一个Scrapy项目:
pip install scrapy scrapy startproject scrapy_project
在Scrapy项目的items.py中定义数据模型,并在spiders/目录下编写爬虫文件。
# scrapy_project/items.py
import scrapy
class ArticleItem(scrapy.Item):= scrapy.Field()
content = scrapy.Field()
# scrapy_project/spiders/article_spider.py
import scrapy
from scrapy_project.items import ArticleItem
class ArticleSpider(scrapy.Spider):
name = 'article_spider'
start_urls = ['https://example.com/news']
def parse(self, response):
articles = response.css('div.article')
for article in articles:
item = ArticleItem()
item['title'] = article.css('h2::text').get()
item['content'] = article.css('p::text').get()
yield item将Scrapy与Django集成
Scrapy爬取的数据需要存储到Django的数据库中,可以通过以下步骤实现:
配置Django设置:在
spider_project/settings.py中添加Scrapy的数据库配置: (图片来源网络,侵删)
(图片来源网络,侵删)DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': 'db.sqlite3', } }创建Django模型:在
spider_app/models.py中定义与Scrapy Item对应的模型:from django.db import models class Article(models.Model): title = models.CharField(max_length=200) content = models.TextField() def __str__(self): return self.title运行数据库迁移:
python manage.py makemigrations python manage.py migrate
修改Scrapy的Pipeline:在Scrapy项目的
pipelines.py中添加Django数据库存储逻辑:from django.db import connection from scrapy_project.items import ArticleItem class DjangoPipeline: def process_item(self, item, spider): article = Article(title=item['title'], content=item['content']) article.save() return item启用Pipeline:在
scrapy_project/settings.py中启用该Pipeline:ITEM_PIPELINES = { 'scrapy_project.pipelines.DjangoPipeline': 300, }
通过Django管理命令运行爬虫
为了方便在Django中调用爬虫,可以创建自定义管理命令,在spider_app/目录下创建management/commands/run_spider.py:
from django.core.management.base import BaseCommand
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
class Command(BaseCommand):
help = 'Run Scrapy spider from Django'
def handle(self, *args, **options):
process = CrawlerProcess(get_project_settings())
process.crawl('article_spider') # 爬虫名称
process.start()运行爬虫的命令为:
python manage.py run_spider
通过Django视图触发爬虫
如果需要通过Web页面触发爬虫,可以在spider_app/views.py中编写视图函数:
from django.http import HttpResponse
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
def run_spider_view(request):
process = CrawlerProcess(get_project_settings())
process.crawl('article_spider')
process.start()
return HttpResponse("Spider is running!")然后在spider_project/urls.py中添加路由:
from django.urls import path
from spider_app.views import run_spider_view
urlpatterns = [
path('run-spider/', run_spider_view, name='run_spider'),
]注意事项
- 异步处理:爬虫是I/O密集型任务,直接在Django视图中运行可能会阻塞请求,建议使用Celery或Django的异步视图(如ASGI)来处理。
- 反爬虫策略:尊重目标网站的
robots.txt,设置合理的请求间隔,使用User-Agent等。 - 数据清洗:在存储到数据库前,对爬取的数据进行清洗和验证。
相关问答FAQs
Q1: 如何在Django中定时运行爬虫?
A1: 可以使用Django的django-crontab库或Celery Beat实现定时任务,在settings.py中添加:
CRONJOBS = [
('0 */6 * * *', 'spider_app.management.commands.run_spider.Command', '>> /tmp/spider.log')
]然后运行:
python manage.py crontab add
Q2: 爬虫运行时如何避免重复爬取?
A2: 可以通过以下方式实现去重:
- 在Django模型中添加唯一约束(如
title字段设置unique=True)。 - 使用Scrapy的
DUPEFILTER_CLASS配置去重中间件。 - 在爬虫逻辑中检查数据库是否已存在相同数据。
if not Article.objects.filter(title=item['title']).exists(): article.save()
文章来源网络,作者:管理,如若转载,请注明出处:https://shuyeidc.com/wp/479923.html<